网易微专业Python高级爬虫工程师【完结】,本套课程涵盖从Python编程基础到高级爬虫开发的完整体系,结合理论与实战,帮助学习者从零掌握网络数据采集技术。课程内容由浅入深,既有Python变量、数据类型、循环、函数、类的系统讲解,也包含Scrapy、Selenium等主流框架的应用,最终延伸到分布式爬虫与反爬破解的实战场景。
课程起步阶段介绍Python的安装与运行环境配置,带领学习者理解变量、数据类型、列表、字典、布尔表达式、条件判断、循环与函数等核心知识点,并通过面向对象的类与实例应用打下扎实基础。
系统讲解网络爬虫的基本原理、计算机网络知识与常用工具,包括Fiddler抓包、requests与urllib库的使用、Ajax数据解析及模拟登录等操作。学员将通过豆瓣读书、百度图片等项目,掌握从静态到动态页面的爬取方法。
深入讲解Scrapy框架的安装与使用,带领学员实操名言网站、网易新闻数据采集。课程还配合SQLAlchemy与MySQL的基础与进阶应用,帮助学员完成数据清洗与存储。
进阶模块围绕多线程、多进程与异步爬虫展开,涵盖threading、multiprocessing、concurrent.futures、asyncio、Celery等高效并发方案。课程通过知乎热榜、百度图片批量下载等案例,让学习者掌握高并发爬取与任务调度。
在实战部分,课程结合真实业务需求,设计了房天下、京东、QQ音乐等平台的数据采集与入库项目,并深入讲解字体反爬破解、代理池搭建、分布式任务调度等核心技巧,全面提升学员的应对能力。
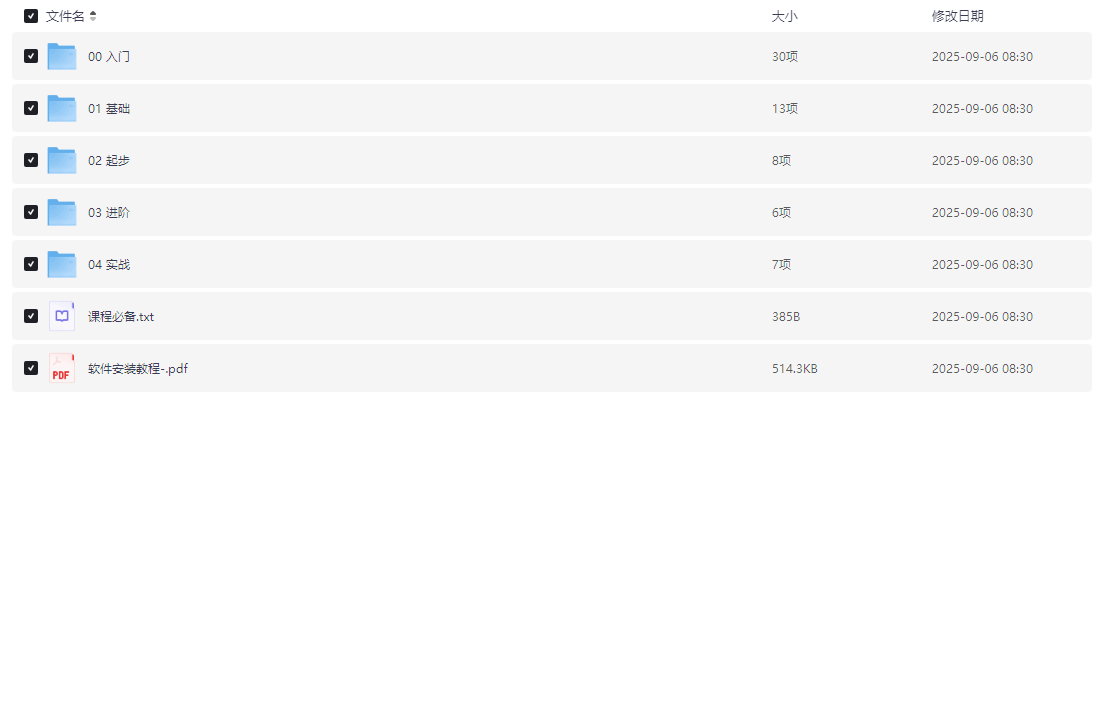
├── 00 入门
├── 01 基础
├── 02 起步
├── 03 进阶
├── 04 实战
├── 课程必备.txt
├── 软件安装教程-.pdf
您好,本帖含有特定内容,请 回复 后再查看。
#免责声明#
本站不存储任何实质资源,该帖为网盘用户发布的网盘链接介绍帖,本文内所有链接指向的云盘网盘资源,其版权归版权方所有!其实际管理权为帖子发布者所有,本站无法操作相关资源。如您认为本站任何介绍帖侵犯了您的合法版权,请发送邮件 kuafuzy@163.com 进行投诉,我们将在确认本文链接指向的资源存在侵权后,立即删除相关介绍帖子!
 学习区
学习区
 【Gaga的富人成交艺术课堂】[9.49GB]
【Gaga的富人成交艺术课堂】[9.49GB]